HW Acceleration
The main goal of the V1 output is to ensure the throughput of 400 Gb/s of high-speed probes providing, in addition to basic security and monitoring functions, also network traffic analysis using machine learning techniques. To achieve the required throughput, a previously designed 400GE card with a powerful FPGA enabling the aforementioned hardware acceleration was used as the target platform (see Figure 1). The goal of hardware acceleration is to accelerate key monitoring and security functions.
 Figure 1: A smart acceleration card containing one 400GE interface, a powerful Intel Agilex FPGA, DRAM memory and a PCIe gen.5 interface. The card was developed as part of a collaboration between CESNET and the French company Reflex CES, which granted CESNET a license to manufacture the cards.
Figure 1: A smart acceleration card containing one 400GE interface, a powerful Intel Agilex FPGA, DRAM memory and a PCIe gen.5 interface. The card was developed as part of a collaboration between CESNET and the French company Reflex CES, which granted CESNET a license to manufacture the cards.
High-speed probes must provide basic monitoring functions in the form of collecting statistical information about network flows (Netflow/IPFIX data), which are also important for behavioral analysis of network traffic. At the same time, they must enable the detection of security incidents using IDS systems that work with extensive rule sets and are very effective in cases where communication is not encrypted. Since the amount of encrypted communication is increasing and IDS systems are of very limited use in the case of encrypted communication, the probe must enable the analysis of encrypted network communication using machine learning techniques. It primarily focuses on exploiting side channels, such as packet length sequences or inter-packet gaps, to address traffic pattern identification or directly detect security incidents. In order to collect evidence about the course of detected incidents, the probe provides precise filtering of network traffic. Filtering is also important for creating new datasets to train newer and more accurate classifiers using machine learning.
Collecting information about network flows
The goal of the collection is to obtain Netflow/IPFIX statistics for individual flows, such as the start and end of communication, the number of packets and bytes. Flows are identified by a combination of IP addresses, ports and protocols. Aggregated data is regularly exported from the ipfixprobe probe 1 to the collector. ipfixprobe is an optimized tool deployed in CESNET for perimeter probes that monitors active connections and updates statistics. For high speeds (100+ Gb/s) it uses an acceleration card for transfers and routing of flows to the same processor cores. To achieve higher performance, hardware acceleration of statistics is required.
The previously proposed acceleration concept 2 takes advantage of the fact that only a small part of “heavy” flows make up the majority of traffic. Moving them to hardware significantly reduces the CPU load. The key element is a hardware Connection Tracking Table with a capacity of millions of records that need to be managed in DRAM or HBM memory on the FPGA. The table must efficiently aggregate statistics for selected flows at speeds of 100–400 Gbps. The selection of flows for acceleration is controlled by ipfixprobe, which continuously synchronizes with the hardware. Thus, ipfixprobe continuously obtains the current connection status.
The acceleration mode selection is described in the diagram in Figure 2. The hardware table can create new flows (DATA state), export them (EXPORT) or switch to NODATA and STAT modes on the command of the software. In DATA state, the hardware sends entire packets with metadata to the software. This allows ipfixprobe to generate IPFIX records and at the same time forward packets to the Suricata IDS. It is possible to limit the size of the packets (e.g. only the first N bytes), which reduces the load on the server. In NODATA mode, ipfixprobe receives only the metadata for the packets. In STAT state, the hardware aggregates statistics and sends summary information about active flows to the software every second. The software performs control and export, while the hardware provides processing. When the connection is terminated (TCP FIN) or the timeout expires, ipfixprobe requests the latest statistics and removes records from the hardware and software tables, which it then exports to the collector.
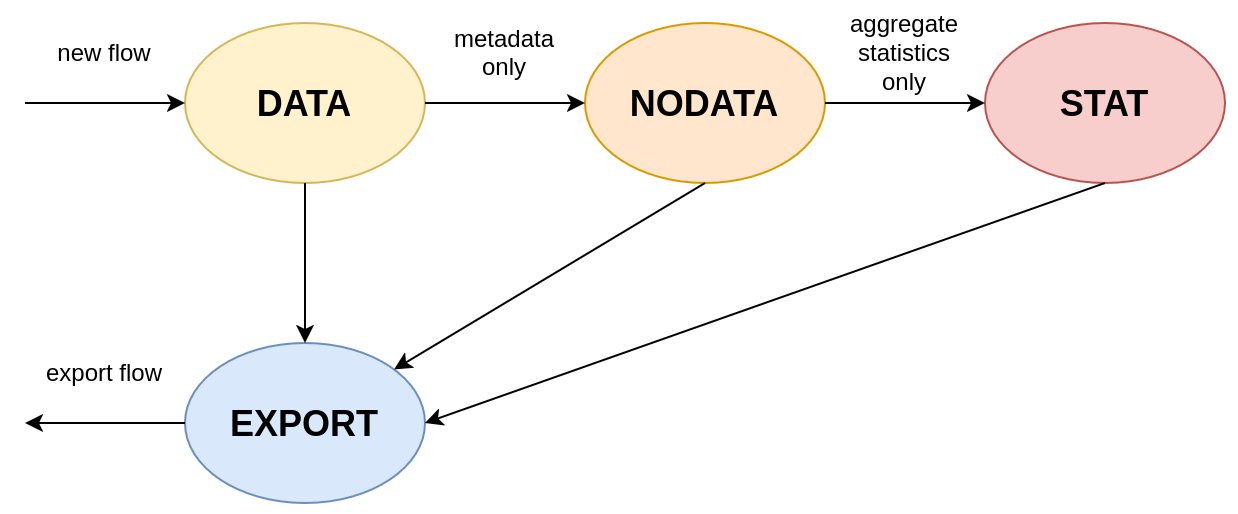 Figure 2: Connection Tracking Table State Diagram.
Figure 2: Connection Tracking Table State Diagram.
Detection of security incidents using IDS Suricata
DS systems are key to network security and, thanks to rule databases, effectively prevent known attacks. Their main advantage is in-depth analysis of network traffic, which also includes packet data and application protocol analysis. However, this analysis is computationally demanding, so it is advisable to accelerate the IDS.
To accelerate, we have developed the 3 system, which significantly reduces the load on the IDS if it can mark some flows as safe and filter them out before entering the IDS. This function is implemented in IDS Suricata as Bypass of network flows. In case of overload, only the beginnings of flows can be analyzed, where most incidents are detected. The IDS then does not analyze all traffic, but still achieves high success rates.
The basis of acceleration is a hardware table of network flows, which allows you to reduce the number of processed flows, which significantly reduces the load and increases throughput. This principle is similar to the acceleration of Netflow/IPFIX statistics collection. The table (Connection Tracking Table) handles millions of flows and filters traffic that the IDS does not want to process, thereby accelerating both statistics collection and incident detection using Suricata.
However, IDS systems are not effective in analyzing encrypted traffic; for TLS, they analyze only the initial headers. To reduce the load, we designed a TLS pre-filter 4 5, which filters encrypted TLS traffic before the IDS. As soon as a TLS record Data indicating the start of encryption appears, data stops being sent to Suricata, which significantly increases throughput. Encrypted flows can also be filtered at the hardware connection table level 6.
We analyzed the hardware acceleration capabilities of Suricata and implemented a connection to DPDK 4 for faster packet acquisition. We also added Bypass functionality and a TLS prefilter in DPDK. The results in Figure 3 show that by software acceleration using DPDK and TLS pre-filtering, the throughput per CPU core almost tripled (from ~500 Mbps to ~1.4 Gbps). A hardware flow table and TLS pre-filtering in hardware will allow Suricata to accelerate even further.
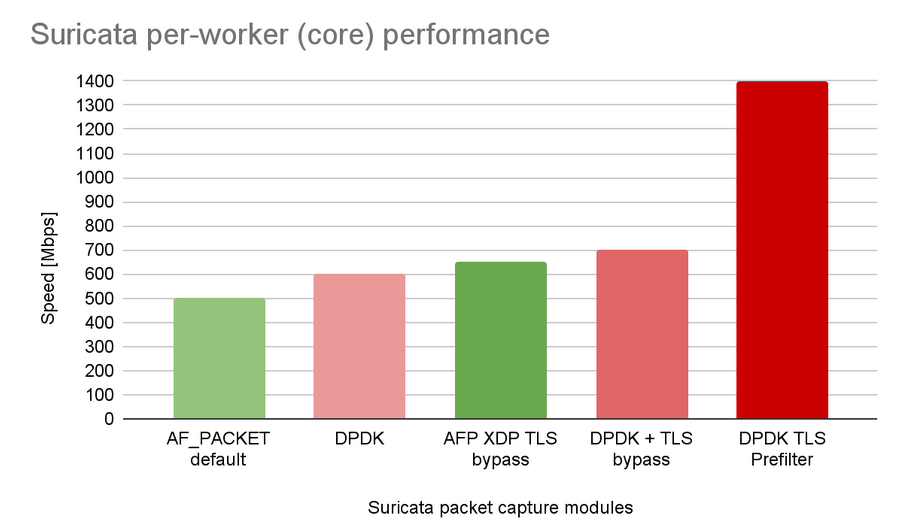 Figure 3: Performance comparison of individual Suricata IDS acceleration techniques in DPDK.
Figure 3: Performance comparison of individual Suricata IDS acceleration techniques in DPDK.
Acceleration of encrypted communication analysis using machine learning techniques
One of the key functions of the probe is network communication analysis using machine learning. Classifiers work with parameters that are extracted from each packet and aggregated into network flows. After deriving the parameters, classification is applied to them, with proven algorithms based on decision trees (e.g. Random Forest, AdaBoost). The calculation and aggregation of parameters takes the most time, which is why hardware acceleration focuses on these operations.
Extracting and aggregating parameters in hardware significantly reduces the volume of data for software. Parameters from one packet are 32–64 B in size, which is about a tenth of the original volume. A 400 Gb/s line thus creates a parameter flow of about 40 Gb/s. Aggregation into network flows (an average of 40 packets per flow) reduces the data by another 40x, which means a final flow of about 1 Gb/s, i.e. a 400x reduction in input data.
For this reduction, it is necessary to implement a modular system for extracting parameters from packets and aggregating them in the network flow table (Connection Tracking Table) in the accelerator card. Each parameter has its own component for extraction and aggregation, which allows flexible support of various parameters according to the requirements of the classifiers.
Parameter extraction is based on the packet parser (Header Field Extractor), payload analyzers (Payload Analyser) and other network information (timestamps, packet length). The Feature Extraction (FE) unit combines the results of the subcomponents into a single vector, which is passed to aggregation in the flow table (Feature Aggregation, FA). FA updates the values and writes them to memory, similar to statistical data.
Despite the significant data reduction (400 Gb/s to 1 Gb/s), it is necessary to ensure that multiple classifiers run on the aggregated data. With an increasing number of classifiers, computational complexity can be a problem even on this reduced flow. Therefore, it is advisable to accelerate classifiers not on the probe, but on the collector, where the data from all probes is. GPU or FPGA can be used for acceleration. Based on experience with hardware acceleration on the probe, we have designed an effective solution designed for acceleration cards with FPGA on the collector.
Precise network traffic filtering
The goal of precise network traffic filtering is to capture network traffic without losing a single packet based on set rules. To prevent uncontrolled packet dropping and to ensure that the captured traffic is lossless, it is necessary to solve the filtering at the hardware level for 400 Gb lines. The CESNET association has already intensively dealt with hardware filtering of network traffic in previous research projects. It has a highly effective filter that is capable of operating at speeds up to 400 Gb/s and is currently deployed in probes protecting 100 Gb lines on the perimeter of the CESNET3 network. The precise filter allows up to 64 general rules and hundreds of specific rules focused on IP prefixes, IP prefixes and TCP/UDP ports and on specific network flows. It was designed to be able to capture data for a detected incident, but it is also easy to use for recording a specific data set. We used the existing filter without modifications in the planned final probe architecture.
Reference
-
CESNET/ipfixprobe. [online] Available at: https://github.com/CESNET/ipfixprobe. ↩
-
KEKELY Lukáš, KUČERA Jan, PUŠ Viktor, KOŘENEK Jan, and VASILAKOS Athanasios. Software Defined Monitoring of Application Protocols. IEEE Transactions on Computers, vol. 65, no. 2, 2015, pp. 615-626. ISSN 0018-9340. ↩
-
KUČERA Jan, KEKELY Lukáš, PIECEK Adam, and KOŘENEK Jan. General IDS Acceleration for High-Speed Networks. In: Proceedings - 2018 IEEE 36th International Conference on Computer Design, ICCD 2018. Orlando: Institute of Electrical and Electronics Engineers, 2019, s. 366-373. ISBN 978-1-5386-8477-1. ↩
-
ŠIŠMIŠ Lukáš and KOŘENEK Jan. Accelerating Suricata with DPDK. Arcachon, 2022. ↩ ↩2
-
ŠIŠMIŠ Lukáš and KOŘENEK Jan. Accelerating Suricata with DPDK Prefilters: 386 Days Later. Athény, 2022. ↩
-
KOŠAŘ Vlastimil, ŠIŠMIŠ Lukáš, MATOUŠEK Jiří, and KOŘENEK Jan. Accelerating IDS Using TLS Pre-Filter in FPGA. In: 2023 IEEE Symposium on Computers and Communications (ISCC). Tunis: IEEE Computer Society, 2023, s. 436-442. ISBN 979-8-3503-0048-2. ↩